Fighting Mode Collapse 1: Feature Matching
In this post, I implement feature matching, a simple technique to mitigate mode collapse in GANs.
What is mode collapse?
Mode collapse is one of the well-known problems in training GANs. In the real world, data distributions are often multimodal (having multiple peaks). In such cases, the generator can fool the discriminator by generating only a single plausible sample from one of the peaks. As a result, when mode collapse occurs, the generator’s output tends to be one or a small number of similar samples.
While experimenting with DCGAN, I ran into this problem myself. These are the real images from the OpenAI Gym CarRacing environment:

And these are the generated images. After a certain point in training, the same image is generated over and over.

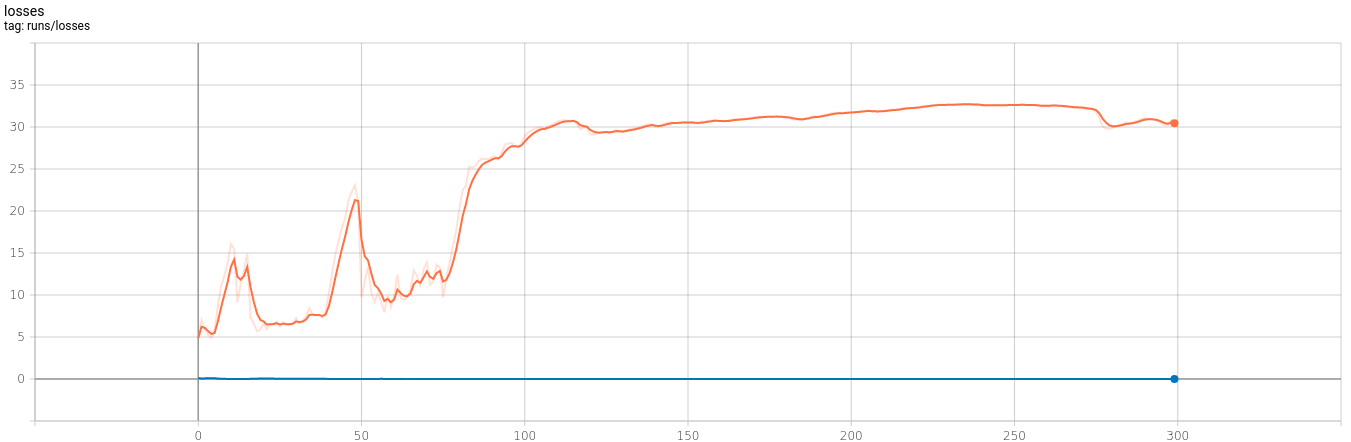
The graph below shows the losses over 300 epochs, indicating that the generator fails to produce realistic data.
Proposed solutions and mitigations
Several mitigations have been proposed in the literature:
- Feature Matching
- Minibatch Discrimination
- WGAN
- Unrolled GAN
In this post, I explore feature matching [1] (and will cover the rest in future posts).
The technique was proposed in “Improved Techniques for Training GANs”. It is fairly simple to implement and straightforward to evaluate.
Instead of directly maximizing the output of the discriminator, the new objective requires the generator to generate data that matches the statistics of the real data, where we use the discriminator only to specify the statistics that we think are worth matching.
With this, the loss function becomes:
\[\left\Vert \mathbb{E}_{x \sim p_{data}} f(X) - \mathbb{E}_{z \sim p_{z}(z)} f(G(z)) \right\Vert^2_2\]where \(f(x)\) denotes activations on an intermediate layer of the discriminator.
Let’s try this out. To implement it, first modify the discriminator to return an intermediate tensor along with the final output.
You can use an existing DCGAN implementation such as the PyTorch tutorial as a starting point. The key change is returning the intermediate tensor:
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 32, 4, 2, 1, bias=False)
self.conv2 = nn.Conv2d(32, 64, 4, 2, 1, bias=False)
self.bn2 = nn.BatchNorm2d(64)
self.conv3 = nn.Conv2d(64, 128, 4, 2, 1, bias=False)
self.bn3 = nn.BatchNorm2d(128)
self.conv4 = nn.Conv2d(128, 256, 4, 2, 1, bias=False)
self.bn4 = nn.BatchNorm2d(256)
self.conv5 = nn.Conv2d(256, 1, 4, 1, 0, bias=False)
self.leaky_relu = nn.LeakyReLU(0.2)
def forward(self, x):
x = self.leaky_relu( self.conv1(x) )
x = self.leaky_relu( self.bn2(self.conv2(x)) )
x = self.leaky_relu( self.bn3(self.conv3(x)) )
x = intermediate = self.leaky_relu( self.bn4(self.conv4(x)) ) # Return intermediate is for feature matching
x = self.conv5(x)
return x.squeeze(), intermediateThen, replace the generator’s BCE loss with MSE and compute the loss as follows:
loss_f_G = nn.MSELoss() # MSE to implement Feature Matching
...
real_out, inter_real = model_D(real_img)
...
out, inter_fake = model_D(fake_img)
loss_G = loss_f_G(inter_real, inter_fake)That is essentially all there is to it. Here are the experimental results:

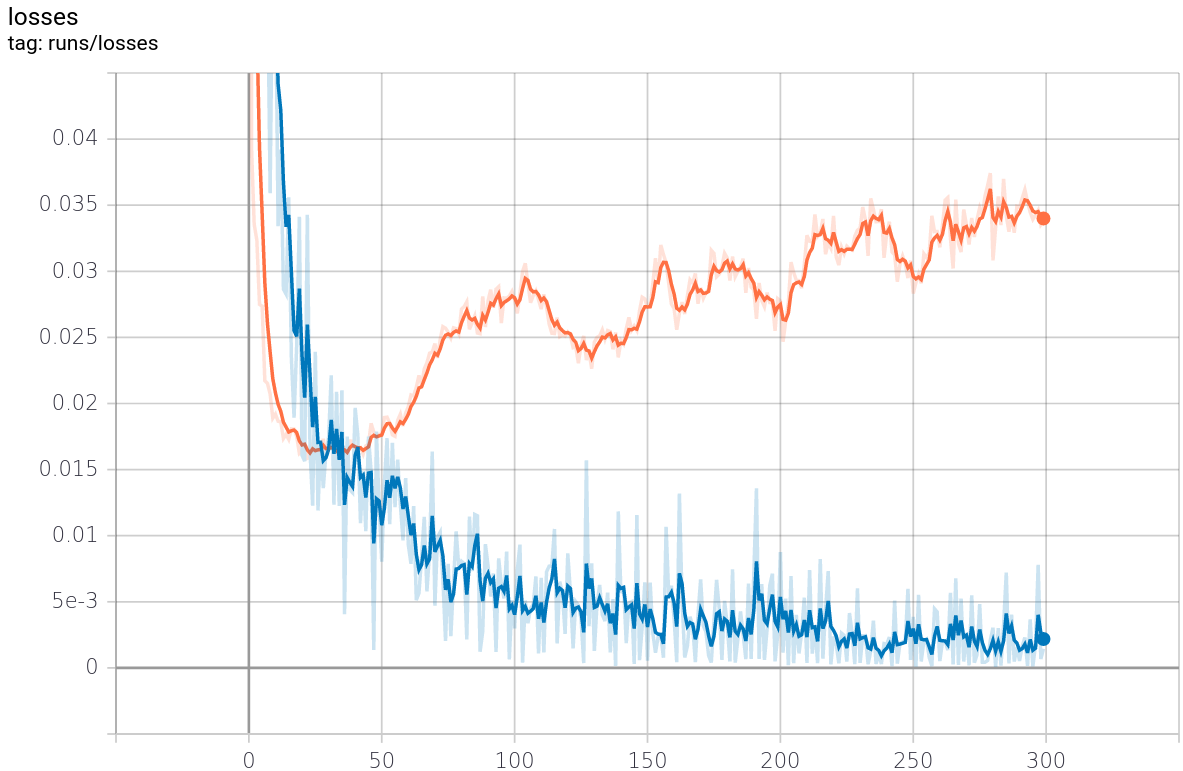
The quality of the generated images is good, and the losses for both the generator and discriminator look stable. This simple technique noticeably improves GAN training.
One thing to note: the generator loss began to rise at a certain point and did not recover. This is one of the challenges in determining when to stop GAN training. I plan to investigate this further.
In this post, I introduced feature matching and confirmed that this simple approach effectively addresses the mode collapse problem. I plan to implement the other techniques in future posts.