Conditional GANs (cGANs) and its variations
Back to basics. As part of my “reinventing-the-wheels” project to understand things deeply, I took some time to reimplement Conditional Generative Adversarial Nets from scratch. This is a note on that process.
Background
The Generative Adversarial Networks framework was introduced by Ian Goodfellow in 2014. Since then, many different types of GANs have been invented, and GANs have been one of the most active research areas in the machine learning community.
A few months after the original GAN paper was submitted, Conditional Generative Adversarial Nets (cGAN) was proposed. According to arXiv, the original GAN paper was submitted on 10 Jun 2014 and the cGAN paper on 6 Nov 2014.
The core motivation of the cGAN paper was that although GANs showed impressive image generation capabilities, there was no way to control or specify the type of image to generate; for instance, generating the digit ‘1’ from the MNIST dataset.
The proposed conditioning method is to simply provide some extra information y, such as class labels, to both the generator and the discriminator.
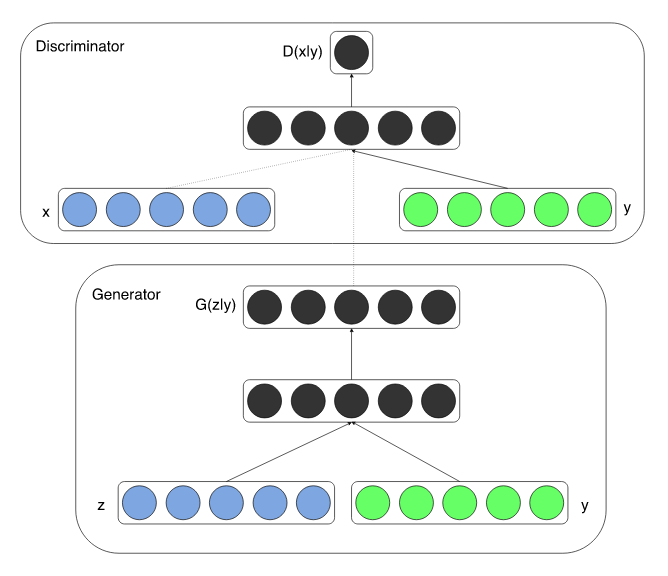 Figure from Conditional Generative Adversarial Nets paper
Figure from Conditional Generative Adversarial Nets paper
The authors demonstrated its effectiveness through MNIST experiments in which the generator and discriminator were conditioned on one-hot class labels.
Implementation
OK, time to code. My implementations: the original GAN (gan.py is the main file; models are defined in models/original_gan.py) and Conditional GAN.
The key differences are:
- Model definition: the input size of the first layer is now
z_dim + num_classes. - Training: concatenate noise
zwith the label, represented as a one-hot vector.
Model definition
class Generator(nn.Module):
def __init__(self, batch, z_dim, out_shape, num_classes):
super(Generator, self).__init__()
self.batch_size = batch
self.z_dim = z_dim
self.out_shape = out_shape
self.num_classes = num_classes
self.fc1 = nn.Linear(z_dim+num_classes, 256) # simple concat
...Similarly, the discriminator is modified to take input images concatenated with a one-hot label.
Training
generated_imgs = generator( torch.cat((z, label), dim=1) )Quick tip: I found torch.Tensor.scatter_ useful for converting integer class labels into N-dimensional one-hot encodings (e.g., converting [3] into [0,0,0,1,0,0,0,0,0,0] where N=10). Since MNIST labels are integers, I convert them into one-hot vectors of shape [batch_size × num_classes] using the following function:
def convert_onehot(label, num_classes):
"""Return one-hot encoding of given list of label
Args:
label: A list of true label
num_classes: The number of total classes for y
Return:
one_hot: Encoded vector of shape [length of data, num of classes]
"""
one_hot = torch.zeros(label.shape[0], num_classes).scatter_(1, label, 1)
return one_hotExperimental results
The left image shows data from a particular batch; the right image shows the generated output conditioned on the corresponding labels.


As you can see, the generated digits in the right image match those in the left. This is because the model is conditioned on the label, allowing it to generate a specific digit. Simple, yet it works.
Further reading
cGANs with Projection Discriminator is an interesting follow-up. The authors propose a novel way to incorporate conditional information into the GAN discriminator.
Rather than simply concatenating additional information to the input vector, they introduce a projection-based approach. Here is the key quote from the paper:
We propose a novel, projection based way to incorporate the conditional information into the discriminator of GANs that respects the role of the conditional information in the underlining probabilistic model. This approach is in contrast with most frameworks of conditional GANs used in application today, which use the conditional information by concatenating the (embedded) conditional vector to the feature vectors.
The figure below compares the main variants of cGANs. (a) is the approach I implemented above; (d) is the projection-based method.
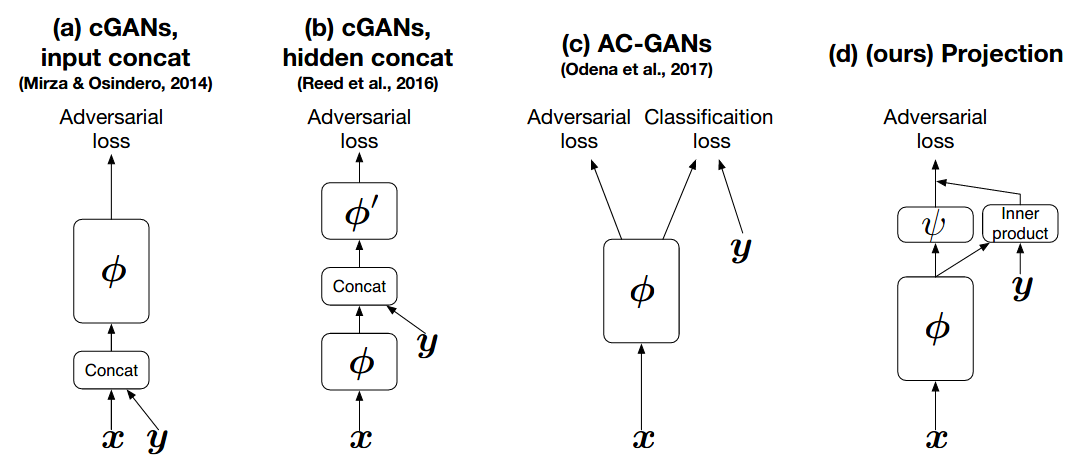 Figure from cGANs with Projection Discriminator paper
Figure from cGANs with Projection Discriminator paper
I plan to implement this approach and write a follow-up post.