Back-to-Basics Weekend Reading - Dropout: A Simple Way to Prevent Neural Networks from Overfittin
I noticed that I have never read the original dropout paper even though it’s very common and I’ve known it for a long time.
Dropout: A Simple Way to Prevent Neural Networks from Overfitting
This technique is well-known for a while to its effectiveness to avoid overfitting of the neural network.
The key idea is as simple as just dripping some network connections randomly during the training. This simple idea “prevents units from co-adaptinig too much” (quote from the paper) which improves generalizability of networks, thus, result in test performance.
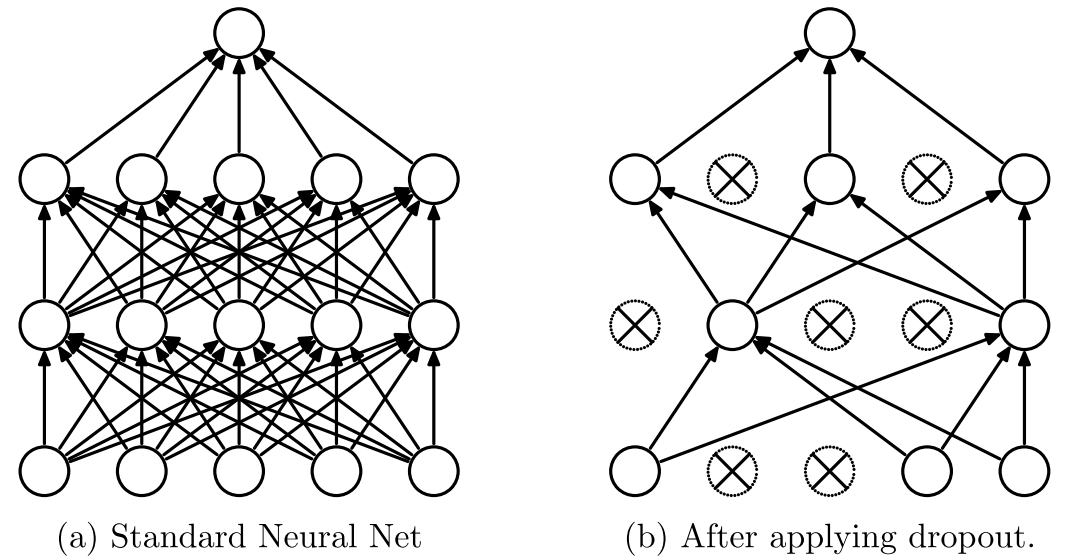
The authors showed that dropout improved the network performance and achieved state-of-the-art performance on SVHN, ImageNet, CIFAR-100 and MNIST.
“The central idea of dropout is to take a large model that overfits easily and repeatedly sample and train smaller sub-models from it” reminds us ‘ensembling’. It’s like we train multiple models (sub-models of the single network is the unique point for dropout) by randomly mute some units. Although you can think of ensembling networks with different architectures and it’ll perform better if you don’t mind some work and computational cost, dropout provides us easier way to get benefits of ensembling.
The cost you need to pay is time. The authors reported that it takes 2-3 times longer to train a network if you have dropout.